







Thông thường khi muốn xây dựng chương trình, bỏ qua những công đoạn khảo sát và đánh giá, chúng ta phải thuật toán hóa được vấn đề. Tức là chúng ta chỉ rõ các bước, các lệnh, các điều kiện, v.v... để thực hiện các tác vụ bằng các dòng lệnh.
Ví dụ quen thuộc là việc giải phương trình bậc 2: ax^2+bx+c=0. Không khó khăn khi chúng ta lập trình giải bài toán với dữ liệu nhập vào là (a,b,c), sau đó tính giá trị delta, rồi xem xét các trường hợp (dùng câu lệnh điều kiện) và cuối cùng xuất ra kết quả để thông báo về nghiệm của phương trình (có thể vô nghiệm).
Những chương trình như vậy được xây dựng trên dòng lệnh dựa trên các luật được chỉ định rõ ràng (hard-code rules). Những ứng dụng như vậy chiếm hầu hết các ứng dụng mà chúng ta gặp như: phần mềm kế toán, phần mềm quản lí nhân sự, phần mềm quản lí thư viện, và vô số chương trình khác. Ngay cả các phần mềm Exel, MS Word, Power Point cũng đều được xây dựng theo cách như vậy.
Nhiều người coi đây là các chương trình được xây dựng bằng cách lập trình truyền thống, để phân biệt với cách lập trình dùng trong Máy học. Bây giờ chúng ta hãy cũng xét xem một ví dụ rất đơn giản nhưng rất khó, nếu không nói là không thể, nếu sử dụng cách lập trình truyền thống giống để xây dựng các chương trình ở trên.
Bạn có thể viết một chương trình để nhận ra sự khác nhau giữa một chú chó và một chú mèo? Cụ thể hơn là chương trình có đầu vào là một ảnh, chương trình cần đưa ra nhận định là chó hay là mèo.
Được thôi, bạn quan sát và nhận thấy rằng chó có mõm dài hơn mèo. Bạn có thể viết chương trình sử dụng rất nhiều luật (if-then, while, for) để thực hiện nhận định đó. Và khi một ảnh một con vật được đưa vào, sau khi chương trình tính toán và đưa ra tỉ lệ của mõm con vật, bạn sẽ xác định được con vật đó là chó hay mèo. Tuy nhiên, chương trình đó sẽ không có tác dụng với ảnh trong Hình 2.

Hình 2. Con nào mõm dài hơn, chó hay mèo?
Được thôi, bạn lại quan sát để không phụ thuộc vào độ dài của mõm và nhận thấy rằng các chú chó cụp tai, còn mèo thì vểnh tai (Hình 3). Bạn sẽ lại viết một chương trình với rất nhiều dòng lệnh để phân biệt được điều đó.

Hình 3. Chó cụp tai, còn mèo vểnh tai.
Tuy nhiên với ảnh trong Hình 4 này thì sao? Thật tiếc, chương trình của bạn lại phán đoán sai!

Hình 4. Chó vểnh tai, còn mèo cụp tai.
Thêm nhiều lần nữa, bạn có thể dựa vào đuôi, dựa vào mũi, lông, hay mắt. Nhưng mỗi lần bạn viết được các chương trình như vậy, thì chính bạn lại đưa ra được rất nhiều phản ví dụ để chương trình của bạn phải viết lại, và chương trình đó cần hàng nghìn các dòng lệnh, mà vẫn không thỏa mãn hết các trường hợp.
Chúng ta muốn hướng tới một chương trình mà thậm chí có thể nhận chính xác những ảnh sau (chúng tôi có hỏi hai trẻ nhỏ 4-5 tuổi và cả hai đều nhận ra chính xác con vật ở 3 Hình 5, mặc dù họ chưa nhìn thấy hình này bao giờ).

Hình 5. Hình khó về chó và mèo.
Và bạn thử hình dung xem chương trình của bạn có thể phân biệt được chó với mèo trong Hình 6 hay không?

Hình 6. Tập ảnh dùng cho cuộc thi trên Kaggle [10].
Như vậy, chúng ta gặp phải ba khó khăn không thể vượt qua khi tiếp cận bằng lập trình truyền thống (hệ chuyên gia dựa trên các luật/câu lệnh được chỉ định rõ ràng):
- Chương trình chúng ta xây dựng đòi hỏi có tính logic rõ ràng để đưa ra các quyết định cho một tác vụ cụ thể. Việc thay đổi rất ít trong tác vụ cũng dẫn tới tác động tới toàn bộ hệ thống đã có.
- Việc thiết kế các luật/câu lệnh đòi hỏi chúng ta phải hiểu rất sâu và rõ tác vụ, để từ đó đưa ra các quyết định phù hợp.
- Khi chúng ta có một bài toán mới (ví dụ phân biệt cam /táo, ôtô/xemáy), chúng ta phải làm tất cả mọi thứ từ đầu. Phù!
Liệu có một giải pháp nào khắc phục được ba khó khăn trên không?
Câu hỏi đặt ra là liệu chúng ta có thể xây dựng một chương trình như mong đợi hay không? Câu trả lời là có! Chúng ta hoàn toàn có thể xây dựng được một chương trình rất tốt (theo nghĩa có độ chính xác cao). Đây chính là một cuộc thi phân biệt giữa chó và mèo trên Kaggle [10]. Khi sử dụng kĩ thuật Deep-learning trong Máy học, độ chính xác có thể đạt tới 99% [11]. Một chương trình có thể tự nhận diện chính xác không kém một đứa trẻ 5 tuổi. Thật là điều tuyệt vời!
Để xây dựng được các chương trình như vậy, chúng ta không có sự lựa chọn thứ hai ngoài Máy học! Chúng ta có thể nói rằng: các thuật toán Máy học không cần chỉ rõ như lập trình truyền thống, mà nó được lập trình để có khả năng tự học. Nhiều bạn tới lúc này sẽ đặt ra câu hỏi: Làm thế nào để một chương trình máy tính có thể đạt độ chính xác cao như vậy? Trong bài toán phân biệt chó và mèo, chúng ta có thể hiểu một cách đơn giản là chương trình Máy học học giống như một đứa trẻ học (4-5 tuổi trong trường hợp phân biệt chó và mèo). Trẻ làm thế nào để phân biệt chó với mèo? Đứa trẻ đó sẽ phân biệt bằng kinh nghiệm. Kinh nghiệm có được từ việc học: học thông qua quan sát thực tế, học qua xem hoạt hình, học qua xem tranh, v.v… Khi trẻ được dạy và quan sát trẻ sẽ tự điều chỉnh để phân biệt được đâu là con chó, đâu là con mèo. Một chương trình máy học là chương trình có cách học … như đứa trẻ vậy. Trong Máy học, chương trình học qua ảnh. Bằng cách học qua rất nhiều ảnh (trong cuộc thi trên kaggle là 25.000 ảnh cho huấn luyện và 12.500 ảnh cho kiểm tra). Hình 7 thể hiện một vài ảnh mẫu trong cuộc thi Kaggle. Sau khi “học” xong, chương trình cũng giống như đứa trẻ có thể nhìn một ảnh để chỉ ra con vật là con chó hay con mèo, mặc dù ảnh đó chưa bao giờ được gặp, dù con vật đó có thể có một vài điểm khác với con vật thực sự chuẩn mực (đầy đủ chân, tai, mắt, kích cỡ phù hợp, …).

Hình 7. Tập ảnh dữ liệu trên tập dữ liệu Kaggle [10].
Để kết thúc phần này, chúng ta hãy xem lại 2 nguyên lí lập trình, một là lập trình truyền thống (Hình 8) và lập trình Máy học (Hình 9 - được lấy từ [9]).
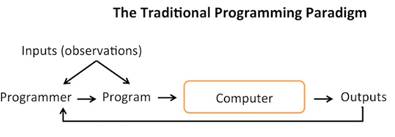
Hình 8. Mô hình lập trình truyền thống.
Trong lập trình truyền thống, người lập trình (Programmer) cần viết chương trình (Program) gồm những luật chỉ rõ máy tính (Program) cần thực hiện để đưa ra kết quả mong muốn. Ngược lại, trong Máy học, Programmer trong máy học viết một chương trình nhỏ để kích hoạt quá trình học thông qua rất nhiều (Inputs, Outputs) nhằm tạo ra một chương trình (Program).

Hình 9. Mô hình lập trình Máy học.
Chúng tôi sẽ sớm trở lại với câu hỏi: Khi nào thì nên sử dụng Máy học?
Tham khảo:
1. https://www.coursera.org/learn/machine-learning
2. Pedro Domingos. A few useful things to know about machine learning, Published by ACM 2012 Article. Volume 55 Issue 10, October 2012, pages 78-87.
3. http://gerardnico.com/wiki/data_mining/bias_trade-off
4. Trevor Hastie. Robert Tibshirani. Jerome Friedman. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer; 2nd ed. 2009. Corr. 7th printing 2013 edition, 745 pages
5. Tom Mitchell. Machine Learning. McGraw-Hill Education; 1st edition, March 1997, 432 pages
6. Stephen Marsland. Machine Learning: An Algorithmic Perspective. Chapman and Hall/CRC; 1st edition April 2009, 406 pages
7. http://drewconway.com/zia/2013/3/26/the-data-science-venn-diagram
8. 10 Machine Learning based Products You MUST see: https://www.youtube.com/watch?v=dcZvhP-IqY4
9. https://sebastianraschka.com/faq/docs/datascience-ml.html
10. https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition
11. http://adilmoujahid.com/posts/2016/06/introduction-deep-learning-python-caffe
12. http://www.forbes.com/sites/85broads/2014/01/06/six-novel-machine-learning-applications/
13. http://yann.lecun.com/exdb/mnist/
14. https://www.youtube.com/watch?v=wr4rx0Spihs
15. https://en.wikipedia.org/wiki/Machine_learning
16. Yaser S. Abu-Mostafa, Malik Magdon-Ismail, Hsuan-Tien Lin. Learning From Data. AMLBook (March 27, 2012), 213 pages.
0 nhận xét:
Đăng nhận xét