






K-nearest Neightbors (KNN) là một trong những thuật toán cơ bản nhất của supervised-learning trong Machine Learning. Hôm nay chúng ta sẽ đi tìm hiểu về KNN thông qua nội dung được dịch từ Introduction to Machine Learning with Python: A Guide for Data Scientists 1st Edition [1].
K- láng giềng (K-nearest Neighbors)
K- láng giềng (K-nearest Neighbors)
Thuật toán k - láng
giềng (k-nearest Neightbor (kNN) ) được cho là thuật toán đơn giản nhất trong
máy học. Mô hình được xây dựng chỉ bao gồm việc lưu trữ dữ liệu tập huấn (training
dataset). Để dự đoán được một điểm dữ liệu mới, thuật toán sẽ tìm ra những láng
giềng trong dữ liệu tập huấn (training dataset), đó là láng giềng (nearest
neightbors).
Phân loại trong K – láng
giềng (K-nearest Neighbors Classification)
Ở mức độ đơn giản, thuật
toán chỉ quan tâm đến duy nhất một láng giềng, đó là điểm dữ liệu tập huấn gần
nhất tới điểm mà chúng ta muốn đưa ra dự
đoán.
Các dự đoán tiếp theo
chỉ đơn giản là đầu ra được biết cho điểm dữ liệu này.
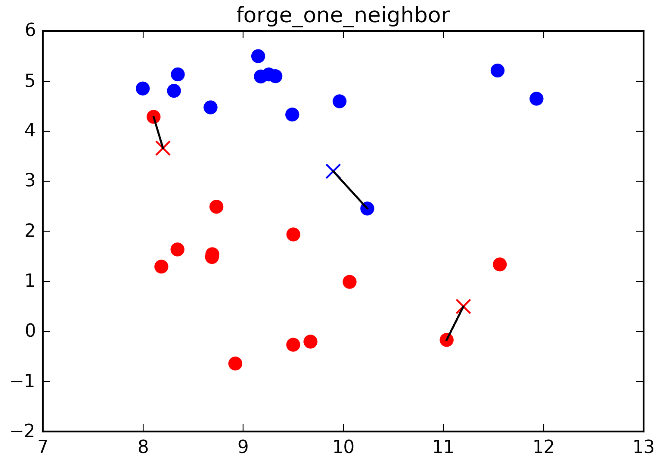
Hình
forge_one_neighbor minh họa điều này cho trường hợp phân loại các tập dữ
liệu.
01.mglearn.plots.plot_knn_classification(n_neighbors=1)
02.plt.title("forge_one_neighbor")
Ở đây, chúng tôi đã thêm
vào 3 điểm dữ liệu mới, được thể hiện bằng các gạch chéo. Với mỗi một điểm,
chúng tôi đánh dấu láng giềng trong dữ liệu tập huấn. Việc thuật toán dự đoán
một láng giềng (one nearest neighbor) chính là gán nhãn cho điểm đó
(được thể hiện bằng màu sắc của gạch chéo).
Thay vì chỉ xem xét một láng
giềng, chúng ta có thể xem xét một số tùy ý $K$ láng giềng. Thuật toán
xuất phát từ chính điểm có tên $K$ của tập láng giềng. Khi xem xét nhiều
hơn một lân cận, chúng ta sẽ sử dụng bình chọn (voting) cho mỗi nhãn
(label). Có nghĩa là, mỗi một điểm tập huấn, chúng ta sẽ đếm xem có bao
nhiêu láng giềng là màu đỏ, và có bao nhiêu láng giềng là màu xanh dương. Sau
đó chúng ta phân chia thêm nhiều lớp (class) : nói cách khác, lớp sẽ
chiếm phần đông trong số k láng giềng.
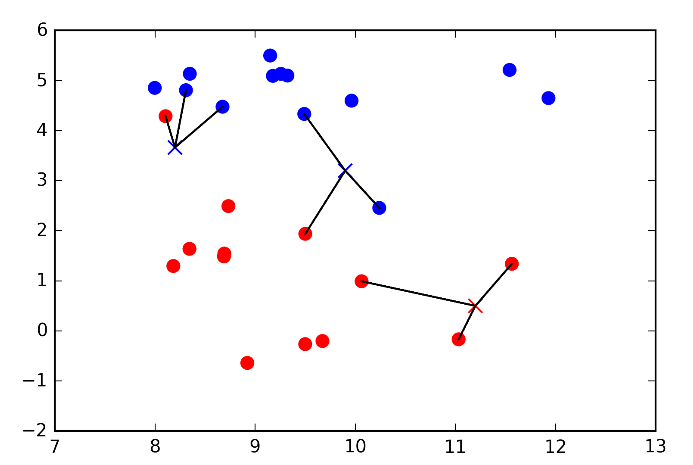
Dưới đây là hình ảnh
minh họa sử dụng 3 láng giềng. Một lần nữa, dự đoán được hiển thị qua màu sắc
của gạch chéo. Bạn có thể thấy rằng dự đoán đã thay đổi cho điểm ở trên cùng
phía bên trái so với khi chỉ sử dụng một láng giềng.
01.mglearn.plots.plot_knn_classification(n_neighbors=3)
Mặc dù trên đây là minh
họa cho bài toán phân loại dạng nhị phân, bạn có thể tưởng tượng rằng nó có thể
làm việc với bất kỳ một lớp số học nào. Đối với nhiều lớp, chúng ta lại đếm có
bao nhiêu láng giềng thuộc từng lớp, và lại dự đoán lớp chung nhất.
Bây giờ hãy xem chúng ta
có thể áp dụng thuật toán $k$ láng giềng( $k$ nearest neighbors)
sử dụng scikit-learn
Đầu tiên, chúng ta sẽ
chia tập dữ liệu thành 2 tập : một tập dữ liệu tập huấn và một tập dữ liệu kiểm
thử.
01.import mglearn as mglearn
02.from sklearn.model_selection import train_test_split [1]
03.X, y = mglearn.datasets.make_forge()
04.X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
Tiếp theo, chúng ta thêm
thư viện và khởi tạo lớp. Chúng ta có thể thiết lập các tham số, như số lượng láng
giềng cần sử dụng. Ở đây, chúng ta đặt nó là 3.
01.from sklearn.neighbors import KNeighborsClassifier [3]
02.clf = KNeighborsClassifier(n_neighbors = 3)
Bây giờ, chúng ta phân
loại để phù hợp với dữ liệu tập huấn. KNeighborsClassifier có tác dụng lưu trữ
tập dữ liệu, vì vậy mà chúng ta có thể tính toán các điểm gần nhất trong thời
gian dự đoán.
01.clf.fit(X_train, y_train)
02.KNeighborsClassifier(algorithm='auto',
leaf_size=30, metric='minkowski',metric_params=None, n_jobs=1, n_neighbors=3,
p=2,weights='uniform')
Để tạo thêm những dự
đoán cho dữ liệu kiểm thử, chúng ta gọi phương thức predict [3]. Phương thức
này sẽ tính toán các phần tử gần nhất trong dữ liệu tập huấn và tìm ra các lớp
chung nhất trong các lớp :
01.clf.predict(X_test)
02.array([1 ,0 , 1 , 0 , 1 , 0 ,0])
Làm sao để chúng ta có
thể đánh giá được mô hình tổng quát, chúng ta sẽ sử dụng phương thức score với
dữ liệu kiểm thử cùng với các nhãn kiểm thử :
clf.score(X_test, y_test)
0.857142857142857
Chúng ta có thể nhìn
thấy mô hình có độ chính xác khoảng 86%, có nghĩa là mô hình dự đoán được chính
xác 86% các mẫu dữ liệu có trong tập dữ liệu kiểm thử.
Phân tích
KNeightborsClassifier
Đối với những tập dữ
liệu hai chiều, chúng ta có thể dự đoán minh họa cho tất cả các điểm thử nghiệm
trong mặt phẳng xy. Chúng ta có mặt phẳng màu đỏ là vùng cho các điểm có màu
đỏ, tương tự với màu xanh. Điều này sẽ cho chúng ta thấy được ranh giới, sự
phân chia giữa nơi có gán thuật toán cho các lớp màu đỏ , và nơi có gán thuật
toán cho các lớp màu xanh.
Đây là một số hình ảnh cho
thấy được ranh giới của một, ba và năm láng giềng:
01.fig, axes = plt.subplots(1, 3, figsize=(10, 3))
02.for n_neighbors, ax in zip([1, 3, 9], axes):
03.clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X, y)
04.mglearn.plots.plot_2d_separator(clf, X, fill=True, eps=0.5, ax=ax, alpha=.4)
05.ax.scatter(X[:, 0], X[:, 1], c=y, s=60, cmap=mglearn.cm2)
06.ax.set_title("%d neighbor(s)" % n_neighbors)
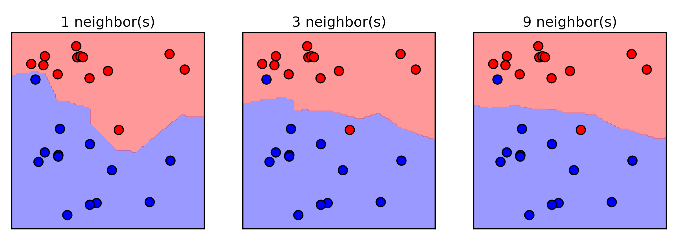
Như bạn có thể thấy
trong hình phía bên trái , sử dụng một láng giềng sẽ cho kết quả là ranh giới
theo sau các dữ liệu. Xem xét ngày càng nhiều các láng giềng thì sẽ dẫn đến
ranh giới thoải hơn. Một ranh giới thoải tương ứng với một mô hình đơn giản. Nói
cách khác, sử dụng ít láng giềng thì dẫn đến mô hình sẽ phức tạp hơn (như thể
hiện ở mô hình bên phải của hình model_complexity), và khi sử dụng nhiều láng
giềng thì tương ứng với sự phức tạp của mô hình thấp (như thể hiện ở mô hình
bên trái của hình model_complexity).
Hãy kiểm tra xem liệu
chúng ta có thể rút ra được mối tương quan nào giữa mô hình phức tạp và mô hình
tổng quát mà chúng ta đã đề cập ở trên hay không.
Chúng ta sẽ làm điều này
với bộ dữ liệu ung thư vú trong thực tế.
Chúng ta sẽ bắt đầu chia
tập dữ liệu ở trên thành 2 tập : một tập dữ liệu tập huấn và một tập dữ liệu
kiểm thử. Sau đó, chúng ta sẽ tìm một biểu thức tập huấn và thử nghiệm với các láng
giềng khác nhau.
01.from sklearn.datasets import load_breast_cancer
02.cancer = load_breast_cancer()
03.X_train, X_test,
y_train, y_test = train_test_split(cancer.data, cancer.target,
stratify=cancer.target, random_state=66)
04.training_accuracy
= []
05.test_accuracy = []
06.# thử n_neighbors
từ 1 đến 10.
07.neighbors_settings
= range(1, 11)
08.for n_neighbors in neighbors_settings:
09.# xây dựng mô hình
10.clf = KNeighborsClassifier(n_neighbors=n_neighbors)
11.clf.fit(X_train, y_train)
12.# Ghi lại độ chính
xác tập dữ liệu tập huấn
13.training_accuracy.append(clf.score(X_train, y_train))
14.# Ghi lại độ chính
xác tổng quan
15.test_accuracy.append(clf.score(X_test, y_test))
16.plt.plot(neighbors_settings, training_accuracy,
label="training accuracy")
17.plt.plot(neighbors_settings, test_accuracy, label="test
accuracy")
18.plt.legend()

Các đồ thị cho thấy độ
chính xác của tập dữ liệu kiểm thử so với các dữ liệu n_neightbors trên trục y
và trục x. Trong thực tế rất ít khi các đồ thị bằng phẳng, chúng ta vẫn có thể
nhận ra được một số đặc điểm của overfitting và underfitting . Khi xem xét ít
hơn láng giềng sẽ tương ứng với một mô hình phức tạp hơn, biểu đồ sẽ được trải
dài theo chiều ngang liên quan đến hình minh họa trong model_complexity.
Xem xét một láng giềng,
dự đoán trên dữ liệu tập huấn là tốt nhất. Xem xét thêm nhiều láng giềng, mô
hình đơn giản hơn, và độ chính xác của tập huấn giảm xuống.
Độ chính xác của tập dữ
liệu kiểm thử khi sử dụng một láng giềng sẽ thấp hơn khi sử dụng nhiều láng
giềng, việc sử dụng một láng giềng sẽ dẫn đến một mô hình quá phức tạp. Nói
cách khác, khi xem xét 10 láng giềng, mô hình sẽ rất đơn giản, và làm giảm hiệu
suất. Hiệu suất tốt nhất sẽ nằm đâu đó là ở giữa, sử dụng quanh 6 láng giềng.
Tuy nhiên , hiệu suất
thấp nhất chính xác khoảng 88 % , điều này có thể chấp nhận được.
Hồi quy trong láng
giềng(k-Nearest Neighbors Regression)
Ngoài ra còn có thuật
toán hồi quy của tập lân cận(k-nearest neighbors). Một lần nữa, chúng ta bắt
đầu sử dụng một láng giềng (1 nearest neightbor), lần này chúng ta sẽ sử dụng
tập dữ liệu wave. Chúng tôi thêm vào 3 điểm dữ liệu kiểm thử có gạch chéo màu
xanh lá trên trục OX.
Sử dụng một láng giềng
để dự đoán chỉ mục tiêu giá trị của láng giềng gần nhất, được thể hiện bằng các
gạch chéo màu xanh dương :
mglear.plots.plot_knn_regression(n_neighbors = 1)

Một lần nữa, chúng ta có
thể sử dụng nhiều hơn một láng giềng để hồi quy. Khi sử dụng nhiều láng giềng
cho hồi quy, dự đoán mang giá trị vừa phải (hoặc trung bình) của các láng giềng
có liên quan :
mglearn.plots.plot_knn_regression(n_neighbors = 3)
Thuật toán láng
giềng(k-nearest neighbors) cho quy hồi được bổ sung trong lớp
KNeighborsRegressor của scikit-learn.
Nó được sử dụng giống
như lớp KNeighborsClassifier :
01.from
sklearn.neightbors import KNeighborsRegressor
02.X, y = mglearn.datasets.make_wave(n_samples
= 40)
03.#chia tập dữ liệu
wave thành 1 tập dữ liệu tập huấn và 1 tập dữ liệu kiểm
thử
04.X_train, X_test,
y_train , y_test = train_test_split(X,y,random_state = 0)
05.# khởi tạo mô
hình, gán giá trị láng giềngbằng 3
06.reg =
KNeightborsRegressor(n_neightbors = 3)
07.# Gộp mô hình sử
dụng dữ liệu tập huấn và mục tiêu tập huấn :
08.reg.fit(X_train,y_train)
09.KNeighborsRegressor(algorithm='auto',
leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=3,
p=2, weights='uniform')
Bây giờ, chúng ta có thể
tạo những dự đoán từ tập dữ liệu kiểm thử :
reg.predict(X_test)
array([-0.05396539,
0.35686046, 1.13671923, -1.89415682, -1.13881398, -1.63113382, 0.35686046,
0.91241374, -0.44680446, -1.13881398])
Chúng ta cũng có thể sử
dụng phương thức score để đánh giá, đối với hồi quy thì kết quả trả về $R^2$
score.
$R^2$ score, còn được
gọi là hệ số xác định, là một cách đo mức độ tốt của dự đoán cho một mô hình
hồi quy, và mang lại một điểm số đến 1. Một giá trị dự đoán bằng 1 tương ứng
với một dự đoán hoàn hảo, và một giá trị 0 tương ứng với một mô hình không thay
đổi chỉ dự đoán trung bình có nghĩa là trả về giá trị trong tập dữ liệu tập
huấn y_trains
reg.score(X_test, y_test)
0.83441724462496036
Ở đây , điểm số là 0.83
cho thấy một mô hình tương đối phù hợp.
Phân tích láng giềng cho
hồi quy ( Analyzing K - Nearest Neighbors Regression)
Đối với tập dữ liệu một
chiều, chúng ta có thể thấy những dự đoán giống tất cả những tính năng có thể
có. Để làm được điều này, chúng ta sẽ tạo tập dữ liệu kiểm thử bao gồm nhiều
điểm trên đường kẻ.
01.fig, axes = plt.subplots(1, 3, figsize=(15, 4))
02.# khởi tạo 1000 điểm
dữ liệu, cách đều nhau trong khoảng -3 và 3
03.line = np.linspace(-3, 3, 1000).reshape(-1, 1)
04.plt.suptitle("nearest_neighbor_regression")
05.for n_neighbors, ax in zip([1, 3, 9], axes):
06.# Tạo những dự đoán
sử dụng 1,3 hoặc 9 láng giềng
07.reg = KNeighborsRegressor(n_neighbors=n_neighbors).fit(X, y)
08.ax.plot(X, y, 'o')
09.ax.plot(X, -3 * np.ones(len(X)), 'o')
10.ax.plot(line, reg.predict(line))
11.ax.set_title("%d neighbor(s)" % n_neighbors)
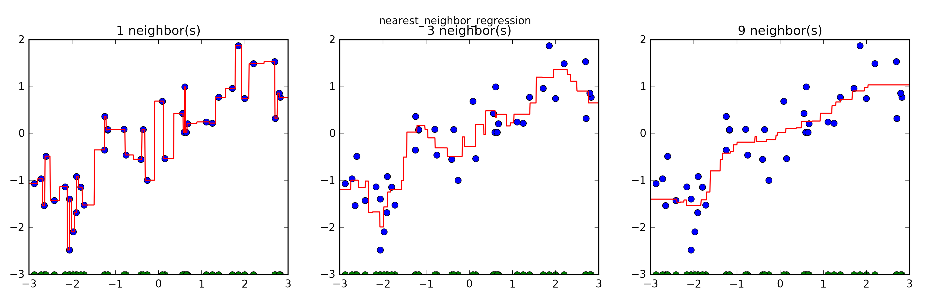
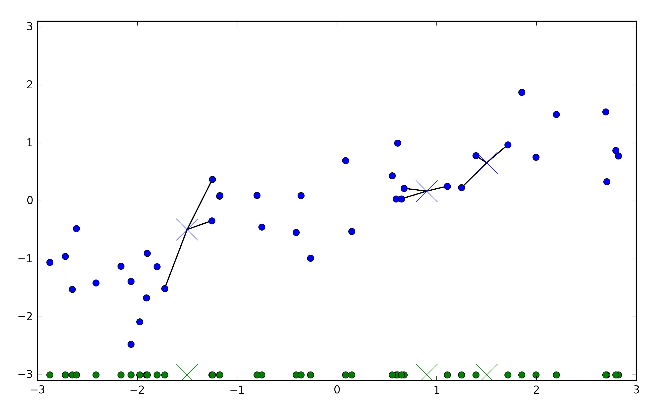
Trong những đồ thị ở trên, những điểm màu xanh
dương là những phản hồi trở lại cho tập dữ liệu tập huấn, trong khi đường màu
đỏ là dự đoán được tạo trong mô hình bởi tất cả những điểm có trên đường đó.
Sử dụng 1 láng giềng, mỗi điểm trong tập dữ liệu
tập huấn đều có sự ảnh hưởng rõ rệt trong những dự đoán, và những giá trị đã dự
đoán vượt ra ngoài tất cả của các điểm dữ liệu. Điều này sẽ dẫn đến một dự đoán
không chắc chắn. Xét nhiều láng giềng sẽ đem lại những dự đoán đều đặn, nhưng
cũng không phù hợp với tập dữ liệu tập huấn.
Những ưu điểm , nhược
điểm và các tham số
Về nguyên tắc, có hai tham số quan trọng trong
KNeighborsClassifier : là số láng giềng và cách bạn đo khoảng cách giữa các
điểm. Trong thực tế, sử dụng một số nhỏ cho láng giềng giống như 3 hoặc 5 sẽ ổn
định hơn, nhưng bạn nên điều chỉnh những tham số này một cách thận trọng. Việc
chọn phương pháp đo khoảng cách phù hợp không nằm trong nội dung của cuốn sách
này. Mặc định, chúng ta sẽ sử dụng khoảng cách Euclidean [4], đem lại hiệu quả
tốt trong nhiều trường hợp.
Một ưu điểm của láng giềng(nearest neighbors)
là mô hình rất đơn giản và dễ hiểu, và thường đem lại hiệu suất hợp lý mà
không cần quá nhiều sự điều chỉnh. Sử dụng thuật toán láng giềng(nearest
neighbors algorithm) là một phương pháp cơ bản để thử nghiệm trước khi sử
dụng những công nghệ cao hơn. Xây dựng mô hình láng giềng(nearest neighbors)
thường rất nhanh, nhưng tập dữ liệu tập huấn lại rất lớn ( về cả số
lượng của tính năng hoặc số lượng mẫu) làm cho dự đoán có thể chậm.
Khi sử dụng láng giềng (nearest neighbors), điều
quan trọng là việc sử lý dữ liệu của bạn (tìm hiểu trong Chương 3 : Học không
giám sát (Supervised Learning). Các láng giềng thường không hoạt động tốt trên
tập dữ liệu đi kèm với rất nhiều tính năng, đặc biệt các tập dữ liệu nhỏ, một
loại dữ liệu phổ biến và chứa nhiều tính năng, nhưng có một số ít tính năng
không dành cho bất kỳ một điểm dữ liệu nào.
Tài liệu tham khảo :
[1]https://www.amazon.com/Introduction-Machine-Learning-Python-Scientists/dp/1449369413
[2]http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html
[3]http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html
0 nhận xét:
Đăng nhận xét